Spark将数据放在jvm堆外导致无故卡死
思路实现与问题产生
咱们内存计算小组陆博的文章Deca经过一年的努力终于中了vldb,作为其中参与了一些微小的工作的男人,虽然对其中一部分细节不是太清楚,因为这个Deca系统的开发涉及到将近5个人,我的工作囊括一下就是:
1.完成了其中UDF的转换,将方法的操作转为对字节数组的操作;
2.手写了Deca的手动版的代码,就是利用Deca的思想对Spark应用的代码进行改造;
3.进行了大量的测试并统计GC时间,stage时间等相关数据.
其实Deca系统的核心思想就是将原有的java大对象转化为字节数组有序地放置在jvm中,这样一可以减少对内存的使用,
也可以基本避免所有的GC.附上论文Deca论文地址
老板的top中了之后,当然会将它扩展扩展然后投期刊,这是基本套路.要求扩展30%,其中就包括将之前的手动版的数据放置在堆外,还是以字节数组的形式来和堆内版本进行比较,理论上来说堆外版本肯定性能是比堆内好的,毕竟放置在堆外可以完全逃避GC的控制,也更加符合Deca的思想.
代码实现并不难,基本由Unsafe这个类操作完成.大概思路就是将Spark应用中需要缓存的RDD其中的partition的对象用字节数组的形式写在堆外,读的时候再直接按照偏移量读取,贴上部
分代码:1
2
3
4
5
6
7
8
9
10
11import UnsafePR._
private val baseAddress = UNSAFE.allocateMemory(size)
private var curAddress = baseAddress
def address = baseAddress
def free:Unit={
UNSAFE.freeMemory(baseAddress)
}
def writeInt(num:Int):Unit={
UNSAFE.putInt(curAddress,num)
curAddress += 4
}
起先在本机的local模式测试了堆外版LR和PageRank应用当然是没问题的,结果也是正确的.然后转移到服务器集群上进行测试.令人惊喜的是,一个神奇的bug出现了.
Bug的特征
此Bug是本人coding以来见识到的算的上奇怪的一个bug了,它有以下几个特征.首先LR的堆外版本集群测试是没有问题的,但是切换到PageRank的堆外版本来测试时,总是在ZipPartition这个stage最后几个task执行的时候jvm crash掉,这个job就直接卡死了,必须手动杀掉才能停止.executor异常日志: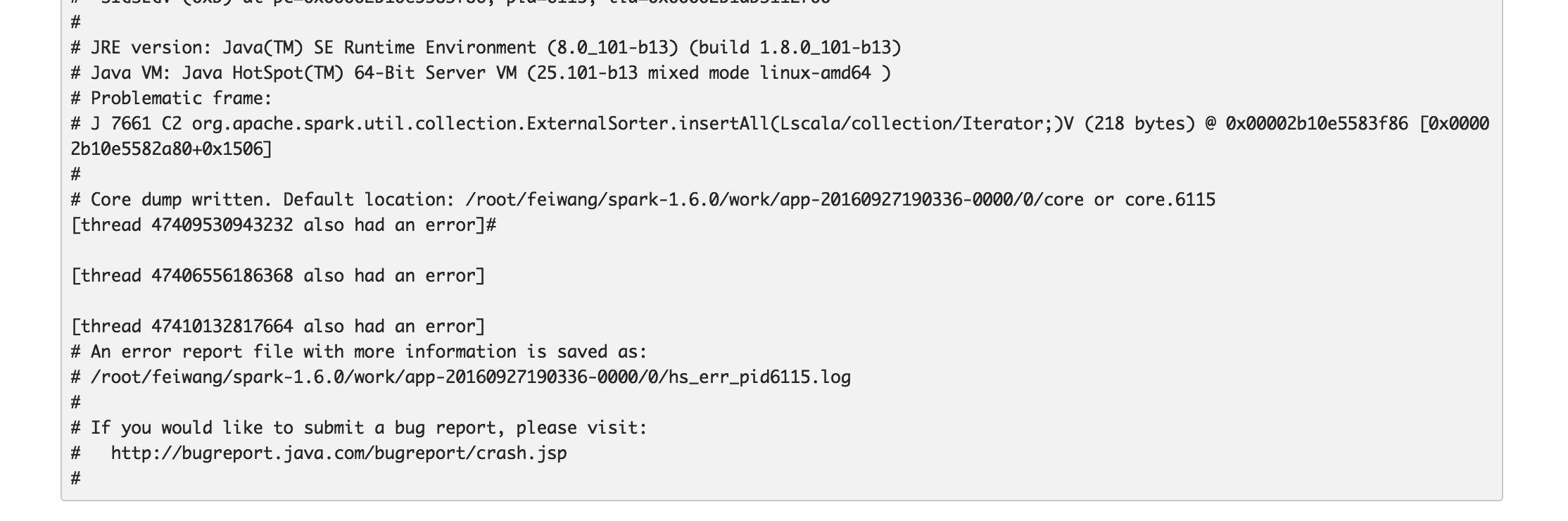
stage卡住图示: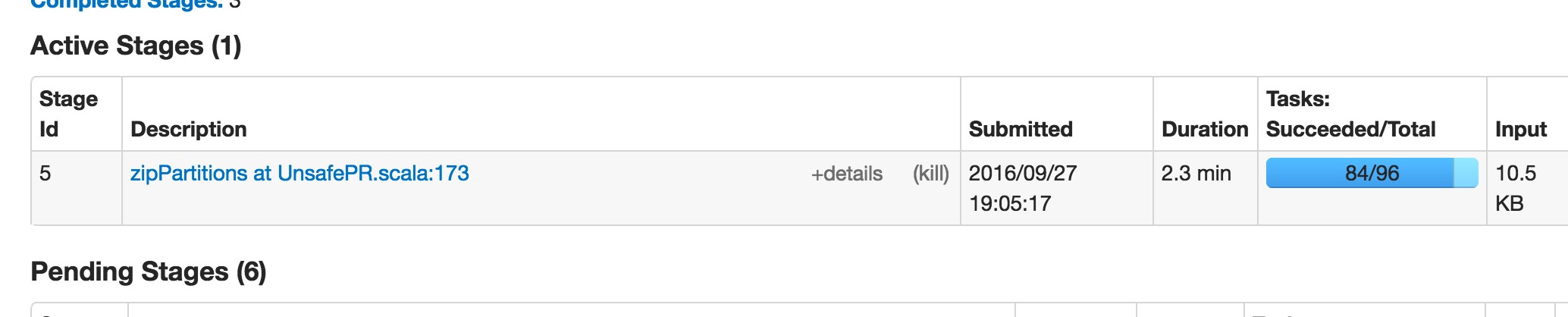
而且还有一个特殊的症状:就是PR跑2G数据量的时候居然不会挂掉,一到7G和20G的时候就会挂掉.而且local模式不会出错,一个executor也不会出错,一旦增加到多个executor就会出错.
Bug原因分析与结论
一开始想到的原因是shuffle的问题,因为local和单个executor不会出错,一旦涉及到网络传输就会报错.我怀疑是不是序列化方式的问题,分别用kryo和java自带的序列化方式测试了一下,然而都会报错.后来想了想应该不是网络传输的问题,不然小数据量怎么可以通过.我上网查了一下jvm crash那段报错信息,基本都是由于Unsafe访问到非法位置的原因,于是开始往这个方向考虑.
最后与师兄讨论中意识到问题的关键所在,首先Spark中一个task在相应的节点没有可空闲的资源来启动task,如果等待一定时间(可配置)还是没有资源则调度到其他节点去执行,也就是non-local task.non-local task是从网络传输过去的,这个策略也就是延迟调度策略.这部分task是由cache RDD的partition生成而来的,这部分task是从block manager过去的,然而partition中的UnsafeEdge对象中只有一个Unsafe成员变量,一个初始地址和终点地址,和分配在jvm堆内的对象不同,并不携带真正的数据.所以这个task被调度到其他executor时,自然会非法访问堆外内存,然后jvm crash掉,这也可以解释为什么stage中位置为Any的task都不能成功执行这个现象.至于2G的数据量为什么可以通过,因为task运行的时间很短,几乎不需要调度就可以在一个executor中全部完成.
所以解决方案就是尽量不让task调度到其他的executor上执行,可以尽量增大spark.locality.wait这个变量来避免出错.
硕大的cache数据
这个就简洁地介绍一下了,这是我大概11月10号遇见的
背景
关于shuffle的VST拆解部分需要加到论文修改中,不过在意外中我发现了之前Deca release1.0版本的一个bug.那就是由于Deca将cache数据的对象完全转化为字节数组存储在jvm中,但是吊诡的现象在于Deca cache的数据居然比原生Spark的还大,这明显是不合理的.初看了一下代码发现是没有问题的.于是联系已经毕业的裴师兄,他说他之前就遇到这个问题了,只不过一直没改.这应该就是传说中的前人挖坑,后人填坑.但我同时也是很兴奋的,因为我们之前手动版本的实验结果很合理,改动Spark内核的自动版本也是同样地思路和流程,但是却出现了这种奇怪的现象,你知道解决bug是一个很能产生成就感的一个举措.在SparkContext将cache的RDD的迭代器做了一次调整,生成一个新的RDD并cache,然后将原本cache的RDD释放掉,重新调整一下RDD链,这样缓存的RDD将会被我们生成的RDD替换掉.之前对缓存的RDD所做的操作是:将里面返回KV对的迭代器改写一下,变换成往一个字节数组缓冲区写字节数组(按顺序写),然后返回新的迭代器.
修复
后来发现之前返回的迭代器基本单位还是一个个KV对,这样就算是按字节数组写了也还是和Spark Cache的数据占用着差不多的大小,于是很简单啦,这里我将一块字节数组区称为CacheChunk,事实上它的类名也是这个.生成CacheChunk后,用Iterator包装一下便返回.跑了一下local模式,结果可想而知,抛出血红色的异常,我用的Idea,不知道其他的编辑器是不是这样.众所周知,Spark的每一个stage的结束要么是ShuffleTask,要么是ResultTask.ShuffleTask需要落磁盘,往block写点什么,这时候出发真正的RDD计算,就是调用RDD的迭代器.当然这里有个判断,如果某个RDD被定义了persist,第一次计算时会将它的计算结果常驻在内存中再返回迭代器,这样下一个stage用到此RDD时便直接在内存中获取,无需计算.管理这个流程的是一个叫CacheManager的哥们,我们之前返回的迭代器是一个iterator,iterator里包含着CacheChunk,CacheChunk里面又有一个迭代器方法,所以CacheManager肯定识别不了了呗.方便,给这个变换的CacheRDD加一个标签变量,切勿不要给它trasient这个标识,它需要被序列化.如果是Deca的RDD便让CacheManager多一个步骤,获取迭代器之后,强制转换为CacheChunk,再取一次迭代器,这样就能获取真正的数据.好,测试通过,perfect.自信地放到集群中去测试,令人”欣慰”的是,cache的数据反而更巨大!
后来怎么办呢,研究CacheManager下面的代码,继续调试往里面跟着走,我只想感叹一句,真的很深…就连一个普通的HashMap Spark都会根据自己的需求改.最后发现RDD的大小的评估是一个SizeEstimator的类实现的,部分功能代码如下:
1 | private def visitSingleObject(obj: AnyRef, state: SearchState) { |
大概思路就是判断对象类型,原生类型直接算,数组就累加算.如果不是原生类型,继续将里面的成员变量入栈,递归调用此函数.当我调试到这儿看调试信息的时候,发现一共访问了有一千多个成员变量,明显不合理.后来发现,CacheChunk里有个Spark定制的IterupptedIterator,这里面带出一批Spark相关的变量,导致评估大小大了整整十几倍.可是CacheChunk是可以不需要这个iterator的,于是将它换了个地方.重新测试,终于okay.流下了喜悦的眼泪,想高歌一曲,想起在实验室便作罢.
之后还遇到CacheChunk自动扩增容量的问题,不过解决起来比较简单,就不在此描述.