Overview
Spark现在已经更迭到2.0了,之前基本都在1.4版本的代码上涂涂改改,着实有点跟不上Spark更新的速度了,最近大概看了Spark2.0相比于1.4更新的点,外壳方面增加了一个SparkSession的类,用户不再显式调用SparkContext了,初看还是挺别扭的。在1.6中加了统一内存管理,比以往更加细粒度的管理内存了,因为内存界限不再是static congigure。
不过之前看到别人的文章在这方面提到过一个弊病,那篇文章的名字叫《向Spark开炮:1.6版本问题总结与趟坑》,名字听着很具有雄性的震慑力,看了之后发现开的炮还是有理有据的,在统一内存管理模块,该文提到:默认情况下executor-memory的75%会拿出来供存储内存和运行内存使用(各占一半),存储内存和运行内存可以相互借用,避免了浪费的情况,有效的提高了内存的使用率。听起来是挺好的,但是运行任务的时候发现了一个问题:存储内存把所有内存占完了,Shuffle的时候它再慢慢从内存中剔除,多浪费了一次加载和剔除的时间。为什么会发生这种情况呢?因为Cache操作发生在Shuffle操作之前,这个时候运行内存是空闲的,它就顺势把运行内存给占完了,有点类似贪心的意味,等进行Shuffle操作的时候,已无内存可用,只能要求存储内存归还。
还有在看Spark1.6的shuffle部分代码时,发现ExternalSorter在插入记录时,内存预估直接决定是否将buffer持久化到磁盘上,而没有了是否要spill的判断,后来看了一下官方的api,果不其然1.6版本移除了这个配置,其实当时就觉得这个功能挺鸡肋的,用户除非有十足的把握shuffle内存足够,不然谁会愿意将spill设置为true,等着程序报错呢。这种判断应该完全交给系统本身去做,虽然系统中也是预估,但总比人为推测靠谱一点。
还有一个大一点的变化是:shuffle版本的不断更迭。在1.5版本时开始Tungsten钨丝计划,引入UnSafe Shuffle优化内存及CPU的使用,大致思想就是将对象存放在堆外,一个很大的好处就是减少GC。在1.6中将Tungsten统一到Sort Shuffle中,实现自我感知选择最佳Shuffle方式到最近的2.0版本,Hash Shuffle已被删除,所有Shuffle方式全部统一到Sort Shuffle一个实现中。到头来还是沿用了mapreduce始祖hadoop的方式,哈哈。下图是spark shuffle版本的演进: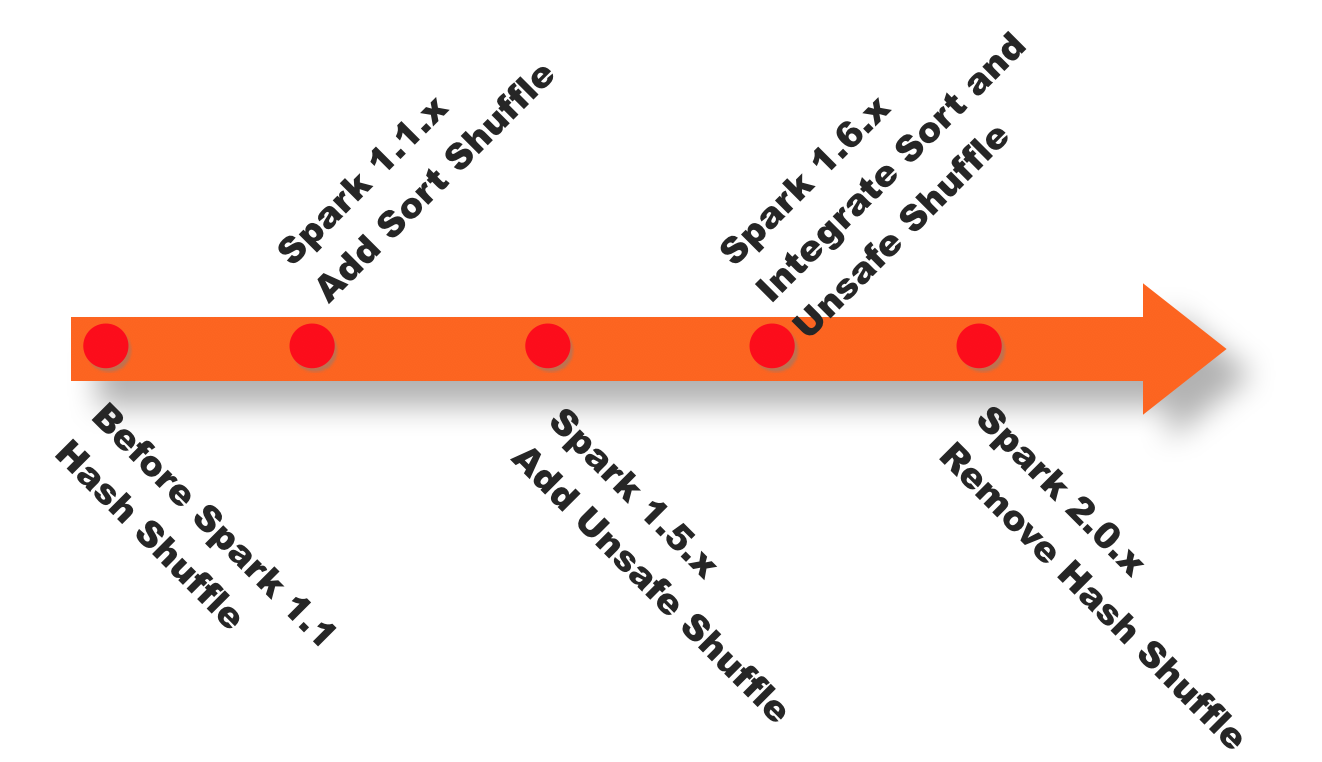
当然新版本更新的特性要比我说得多得多,我只是拿我自己看到的一些点说一下.上面这些并不算赘述,恰恰是想说Spark是一个非常有活力的系统,它的很多特性都在保持着探索更佳的状态,但是不可忽略的一点是,它的一些核心思想不会变,所以看老版本的代码并不会让你觉得在浪费时间,而会让你在看到新版本的时候有更多的感悟。之前因为Shuffle部分的代码看得比较多,也改了挺多。所以在此想总结点自己不太熟悉的东西,关于Spark的job提交与执行的机制(代码来自于Spark-1.6版本)。
在此盗一张关于调度的架构图:(此图来源于github地址)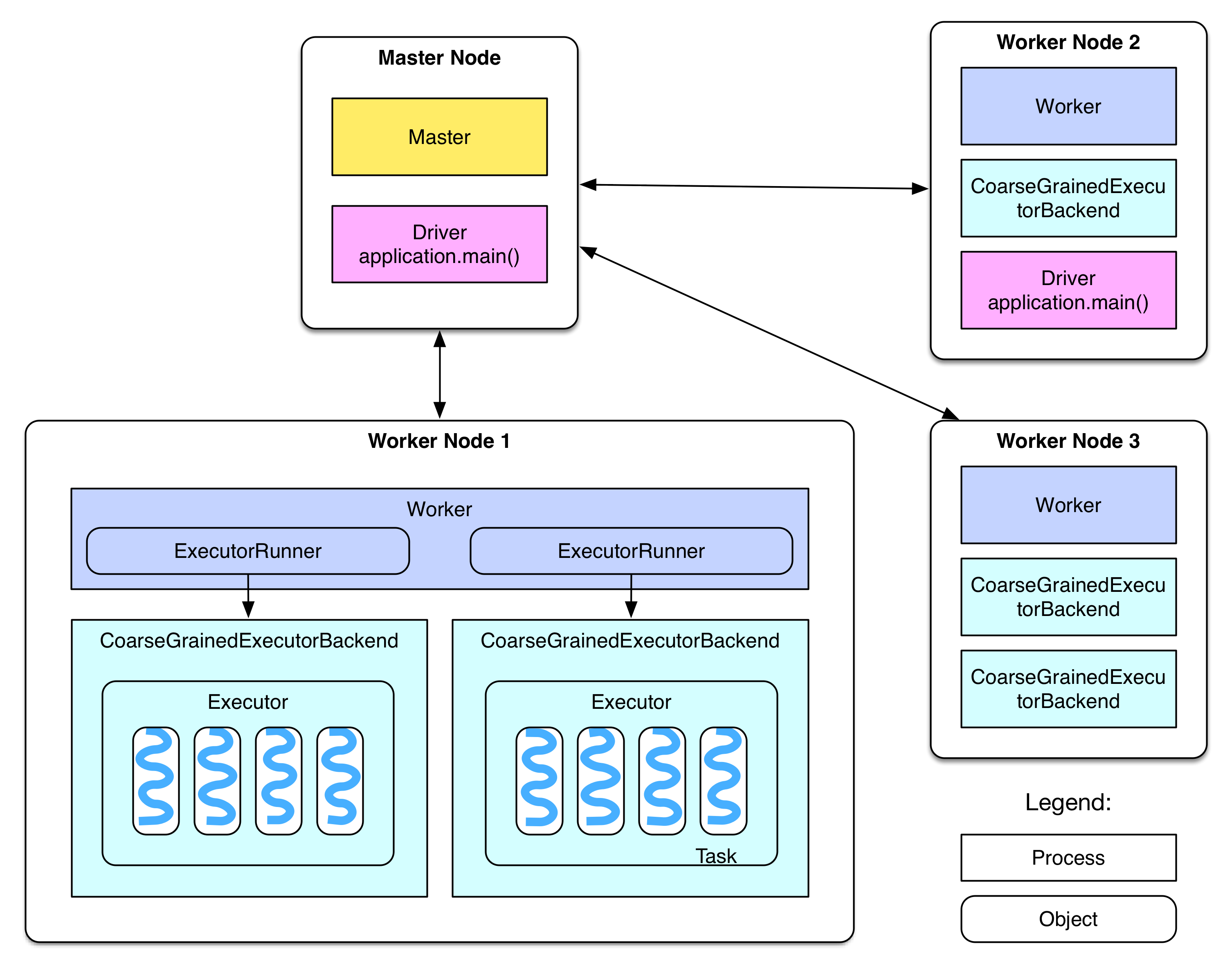
关于Job
job->task的运行过程
job的提交需要action算子的触发,一个作业可以包含多个job。job会从后往前遍历RDD,以shuffle dep来划分stage,stage拆分为一组Task然后提交。
driver端调用顺序
finalRDD.action()
=> sc.runJob()// generate job, stages and tasks
=> dagScheduler.runJob()
=> dagScheduler.submitJob()
=> DAGSchedulerEventProcessLoop.post(JobSubmitted)
=> dagSchedulerEventProcessLoop.doOnReceive(case JobSubmitted())
=> dagScheduler.handleJobSubmitted()
=> finalStage = newStage()
=> mapOutputTracker.registerShuffle(shuffleId, rdd.partitions.size)
=> dagScheduler.submitStage()
=> missingStages = dagScheduler.getMissingParentStages()
=> dagScheduler.subMissingTasks(readyStage)// add tasks to the taskScheduler
=> taskScheduler.submitTasks(new TaskSet(tasks))
=> schedulableBuilder(fifo or fair).addTaskSetManager(taskSet)// send tasks
=> CoarseGrainedSchedulerBackend.reviveOffers()
=> driverActor ! ReviveOffers
=> CoarseGrainedSchedulerBackend.makeOffers()
=> CoarseGrainedSchedulerBackend.launchTasks()
//之间有通信
=> foreach task
CoarseGrainedExecutorBackend(executorId) ! LaunchTask(serializedTask)
解释一下最后的分配Task
sparkDeploySchedulerBackend接收到taskSet后,会通过自带的DriverActor将serialized tasks发送到调度器指定的worker node上的CoarseGrainedExecutorBackend Actor上。
Worker 端接收到 tasks 后,执行如下操作
coarseGrainedExecutorBackend ! LaunchTask(serializedTask)
=> executor.launchTask()
=> executor.threadPool.execute(new TaskRunner(taskId, serializedTask))
executor将task包装成taskRunner,并从线程池中抽取出一个空闲线程运行task。一个CoarseGrainedExecutorBackend进程有且仅有一个executor对象。
一个应用程序就会启动一个新的backend进程。
Executor接收到序列化的task后,先反序列化,然后运task得到其执行结果directResult,这里的directResult一般是ShuffleMapTask或者是ResultTask。ShuffleMapTask返回的是MapStatus,包含了BlockManagerId和block的大小;还有一种情况是ResultTask,是func在partition上的执行结果。这个结果要送回到driver那里,但是通过Actor发送的数据包不易过大,如果result比较大(比如groupByKey的result先把result存放到本地的“内存+磁盘”上,由blockManager来管理,只把存储位置信息(indirectResult)发送给driver,driver需要实际的result的时候,会通过HTTP去fetch。如果result不大(小于spark.akka.frameSize=10MB),那么直接发送给driver。
Driver收到task的执行结果result后会进行一系列的操作:首先告诉taskScheduler这个task已经执行完,然后去分析result。由于result可能是indirectResult,需要先调用blockManager.getRemoteBytes()去fetch实际的result。
得到实际的executor执行的result后,需要分情况分析,如果是ResultTask的result,那么可以使用ResultHandler对result进行driver端的计算(比如 count()会对所有ResultTask的result作sum),如果result是ShuffleMapTask的MapStatus,那么需要将MapStatus(ShuffleMapTask输出的FileSegment的位置和大小信息)存放到mapOutputTrackerMaster中的mapStatuses数据结构中以便以后reducer shuffle的时候查询。
在ShuffleMapTask执行完获得MapStatus的时候,在DAGScheduler类中handleTaskCompletion的方法中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16case smt: ShuffleMapTask =>
val shuffleStage = stage.asInstanceOf[ShuffleMapStage]
updateAccumulators(event)
val status = event.result.asInstanceOf[MapStatus]
val execId = status.location.executorId
logDebug("ShuffleMapTask finished on " + execId)
if (failedEpoch.contains(execId) && smt.epoch <= failedEpoch(execId)) {
logInfo(s"Ignoring possibly bogus $smt completion from executor $execId")
} else {
shuffleStage.addOutputLoc(smt.partitionId, status)
}
。。。
mapOutputTracker.registerMapOutputs(
shuffleStage.shuffleDep.shuffleId,
shuffleStage.outputLocInMapOutputTrackerFormat(),
changeEpoch = true)
下一个stage如何获取Shuffle文件
reducer首先要知道parent stage中ShuffleMapTask输出的FileSegments在哪个节点。这个信息在ShuffleMapTask完成时已经送到了driver的mapOutputTrackerMaster,并存放到了mapStatuses:HashMap(一种特殊的hashmap)里面,给定stageId,可以获取该stage中ShuffleMapTasks生成的FileSegments信息Array[MapStatus],通过Array(taskId)就可以得到某个task输出的 FileSegments位置(blockManagerId)及每个FileSegment大小。
这里涉及的类有点多,在此就不一一赘述。
关于reduce要怎么读reduce文件:1
2
3
4
5SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
.read()
.asInstanceOf[Iterator[(K, C)]]
。。。
mapOutputTracker.getMapSizesByExecutorId(handle.shuffleId, startPartition, endPartition)
这里Spark-1.6和1.4版本调用的方法不太一样,但思想大致相同。reduce Task读取shuffle文件时还是根据partition id来规定起始和结束的partition,一个Reduce Task只读取shuffle文件中的一部分,也就是其中的一部分key。startPartition和endPartition会相应的映射为block id便于读取。
真正根据block id读取远程文件的代码在ShuffleBlockFetcherIterator的sendRequest方法里,挺难找的。。由于各种迭代器加上scala的语法糖1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22val address = req.address
shuffleClient.fetchBlocks(address.host, address.port, address.executorId, blockIds.toArray,
new BlockFetchingListener {
override def onBlockFetchSuccess(blockId: String, buf: ManagedBuffer): Unit = {
// Only add the buffer to results queue if the iterator is not zombie,
// i.e. cleanup() has not been called yet.
if (!isZombie) {
// Increment the ref count because we need to pass this to a different thread.
// This needs to be released after use.
buf.retain()
results.put(new SuccessFetchResult(BlockId(blockId), address, sizeMap(blockId), buf))
shuffleMetrics.incRemoteBytesRead(buf.size)
shuffleMetrics.incRemoteBlocksFetched(1)
}
logTrace("Got remote block " + blockId + " after " + Utils.getUsedTimeMs(startTime))
}
override def onBlockFetchFailure(blockId: String, e: Throwable): Unit = {
logError(s"Failed to get block(s) from ${req.address.host}:${req.address.port}", e)
results.put(new FailureFetchResult(BlockId(blockId), address, e))
}
}
最后以规定的反序列化方式来读取KV对装载进iterator返回给ShuffleReader完成后续的操作。
总结
代码贴得有点多,可能不便阅读,但是Spark里面一个方法里经常完成了许多动作,因为考虑的因素太多,所以写得很细致,很多情况下一个方法里就包含了很多判断和容错操作,全靠文字描述可能要花很大篇幅。附上代码也便于以后自己的回顾,在最短的时间找到我想看到的部分。在开篇说不提shuffle,还是提到了一部分,毕竟它也是job执行的重要环节,不过也只介绍了个大概。