一实践是检验真理的唯一标准
背景
我们架构底层有一个分布式的任务调度和执行系统,名叫Alisa, 女神之意。当下发到上面的任务运行到中间态or终态时,会将任务的状态回调给依赖的外部服务。系统中存在一个任务回调线程池,多个TaskCallbackThread分别捞取回调任务数据(TaskCallback),接着处理任务的回调流程;回调外部服务(CallbackTarget)成功后则正常移除回调任务,若回调失败,则生成重复回调任务,扔到重试回调线程池,由多个RetryCallbackThread去处理,默认有5个重试回调线程(数量较少),若回调仍然失败,则继续排队由重试回调线程处理。
问题出现
由于现在任务回调线程一次会批量捞取上百个回调任务进行回调,并且频繁捞取。回调任务集合中包含要回调给各种CallbackTarget,其中包括调度,数据集成,ide等。
问题是: 若某一段时间某个外部CallbackTarget出现问题(rt高等原因),一次回调时间过长(ex.超过3s)。这时候回调任务线程处理该类回调任务时,会严重阻塞后面正常CallbackTarget的回调任务。且后续还有异常服务的回调任务,导致延迟越来越严重,整体回调会严重变慢。比如2019年5月31日和2018年的某一天,由于数据同步服务的异常,导致其他服务运行任务状态回写受到阻塞,任务状态更新变慢,最后用户的反馈就是任务一直等待资源或者一直在运行中。
任务回调的队列模拟图: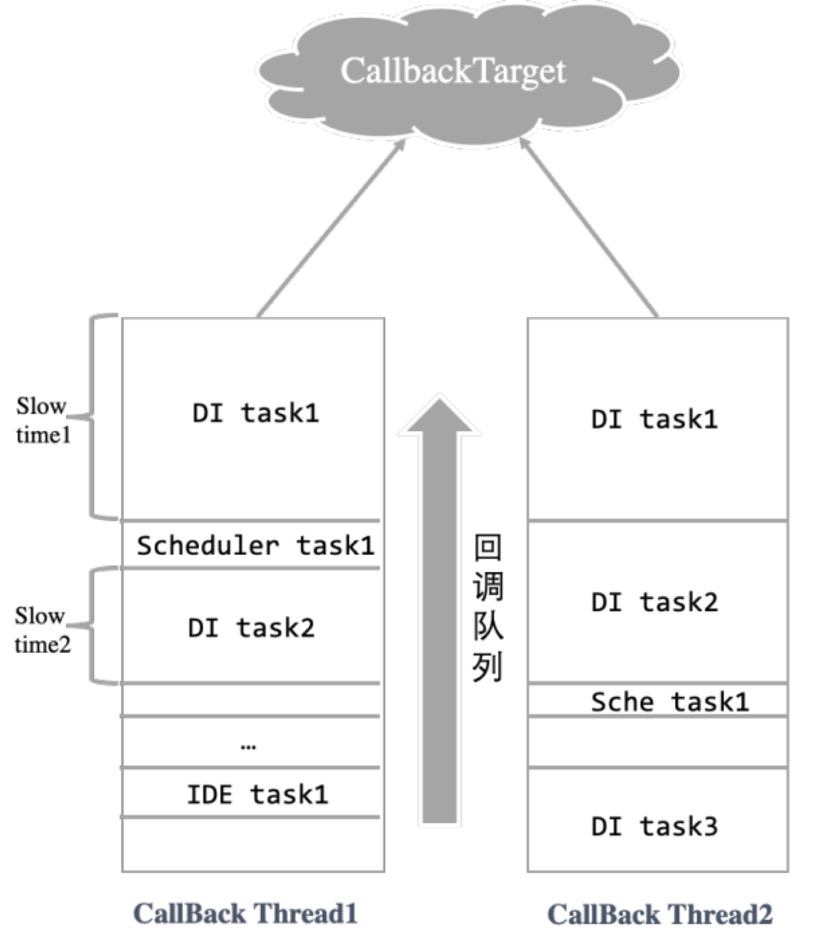
服务分组回调方案
针对每个CallbackTarget的回调任务划分到不同线程组去处理回调, 不同CallbackTarget的回调任务不会互相影响。
缺点:
(1)回调的CallbackTarget多了很不利于扩展; (2)不同的CallbackTarget所需要回调的任务量不同,会造成部分线程较长时间空闲,部分线程任务量很大。负载不均衡。
基于服务异常感知的任务回调方案
提出一种自适应地感知异常CallbackTarget,提前将异常CallbackTarget的回调任务做特殊处理,不阻塞正常CallbackTarget的任务回调。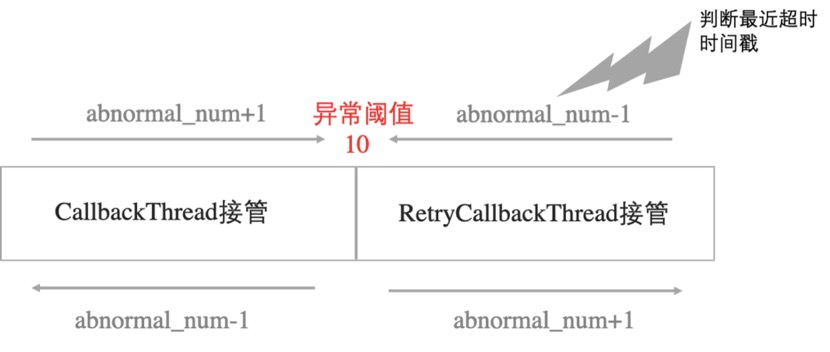
(1)数据结构:
在内存中维护一张异常服务映射表,key为外部url,value存储(abnormal_num,abnormal_time),abnormal_num为超时任务出现次数,abnormal_time为超时任务出现的最近时间。[callbackUrl, (abnormal_num,abnormal_time)].
(2)异常处理策略:
这里的异常指的是回调超时,无论最后回调成功or失败。
判断一个超时任务的标准:
某个任务在回调前和回调完成后的时间差,不管是否异常,只感知和记录超时任务(异常任务也可以回调时间很短,不会阻塞回调流程)。
模拟一个异常次数滑动窗口,假定中间值为10也就是异常阈值,总长度为20最大阈值。当TaskCallbackThread处理回调任务之前,当遇到超时任务时,则将该超时任务的回调地址对应的abnormal_num+1,abnormal更新为最近时间。当超时任务连续增加到异常阈值10时,判断该CallbackTarget已经开始异常。则下次再碰到该CallbackTarget的任务时(通过判断映射表),则不处理回调操作,直接将该CallbackTarget的回调任务扔给RetryCallbackThread去处理。(如此该异常CallbackTarget后续的回调任务直接交给RetryCallbackThread去处理,不会阻塞后面排队的正常CallbackTarget的任务。) RetryCallbackThread处理回调任务时如果继续失败,首先判断异常服务映射表对应的次数是否大于10,大于10开始对其进行更新操作,继续对其进行累加,并更新时间戳,直至增加到最大阈值20, 往后不再增加,只更新abnormal_time。
(3)恢复策略:
服务总有恢复正常的时候,不能一直将曾经异常的CallbackTarget对应的回调任务扔给RetryCallbackThread处理,否则异常CallbackTarget多了会导致所有回调任务都会交给RetryCallBackThread处理。所以滑动窗口还需要能感知到服务恢复正常,方法是当接收到非超时任务时,abnormal_num减1,当减到10至10以下时,则TaskCallbackThread重新接管已恢复正常的CallbackTarget,按照正常流程去处理该CallbackTarget的回调任务。如果回调任务依然未超时,则持续性将abnormal_num减至0。若再一次有超时任务,继续加1,到达10以上继续交给RetryCallbackThread处理该CallbackTarget的任务回调。
(4)防止服务间歇性异常
一种特殊情况是,在一段时间内,回调给某CallbackTarget的请求,时而超时,时而正常,比如某台机器故障导致。这时候异常次数滑动窗口会发生抖动,可能异常次数一直徘徊在10以内,导致无法进入异常处理流程。解决方案就是利用abnormal_time来判断,当回调任务时发现未超时任务时,还要计算abnormal_time和当前时间的差值,超过一定阈值T时,才能假定该CallbackTarget已经恢复一段时间,abnormal_num才可以回减。
优势:无视有多少个CallbackTarget,统一处理。方案定义的阈值可凭借经验值更改配置。能应变多种极端情况。还有很多优势就不一一列举,总之很强很鲁棒。
一些后续的话
其实很多方法都来源于生活,基于服务异常感知这种方案其实生活和社会中也有类似的参照,大家可以感受一下。