一天下武功,无坚不破,唯快不破。 --—火云邪神
背景
如果简单的说任务执行引擎,那涵盖的范围将会很广,这篇主要谈的是基于工作流的离线任务调度执行系统。离线的反面便是在线,在线意味着用户提交个作业或请求要求立即返回,需要极低的延迟,而处理巨大数据量的计算需要较漫长的时间,用户提交一个计算作业后便可以放置处理其他的事情,拿我们平台来说,大部分提交的作业属于小时作业和天作业,较长可以达到一周,当然平台会有监控限制,超过限制时长会直接杀掉任务。基于用户的习惯和数据特性,整点就成为了作业狂欢的时刻。
整点尤其0点系统负载是最令人恐慌的,别人的系统热闹都在大白天,只有我们是深夜的哨兵,夜里的12点左右基本是不睡的,是昂首挺胸站在床上迎接告警短信们的到来。说到告警短信,刚入职时凭着那份新鲜劲一收到告警短信肾上腺素仿佛从嗓子眼里喷出来,立马整个人血管喷张。而新鲜感总会离开,像你脚下的河流,抬头看到的云, 镜子中年轻的你。现在再看到告警短信,整个上半身和下半身都是耷拉的状态,心里默念一声嗯?甚至都不会默念。倒不是因为自己身经百战见得多,只是发现大部分告警短信(优化有效告警乃当务之急!!),就像每家商店门口的欢迎光临。
随着上层工作流调度系统的分布式化,整个任务下发在整点时愈发疯狂,执行引擎是依赖RDS的,0点洪峰任务下发伴随十万匹角马踏着彩虹桥而来,无情地践踏服务。这么一说,我们系统每天0点都仿佛经历一次微型双十一。一个任务过来,意味着若干个流程和写库操作,整个流程下来较为耗时, 在整点高吞吐的要求下,系统整体因为分布式可扩展可以扛得住,但RDS也可能扛不住, 观察指标发现,RDS的TPS很高。脱口而出: 要有缓冲区, 削峰填谷。年长的同事说: 很好的废话。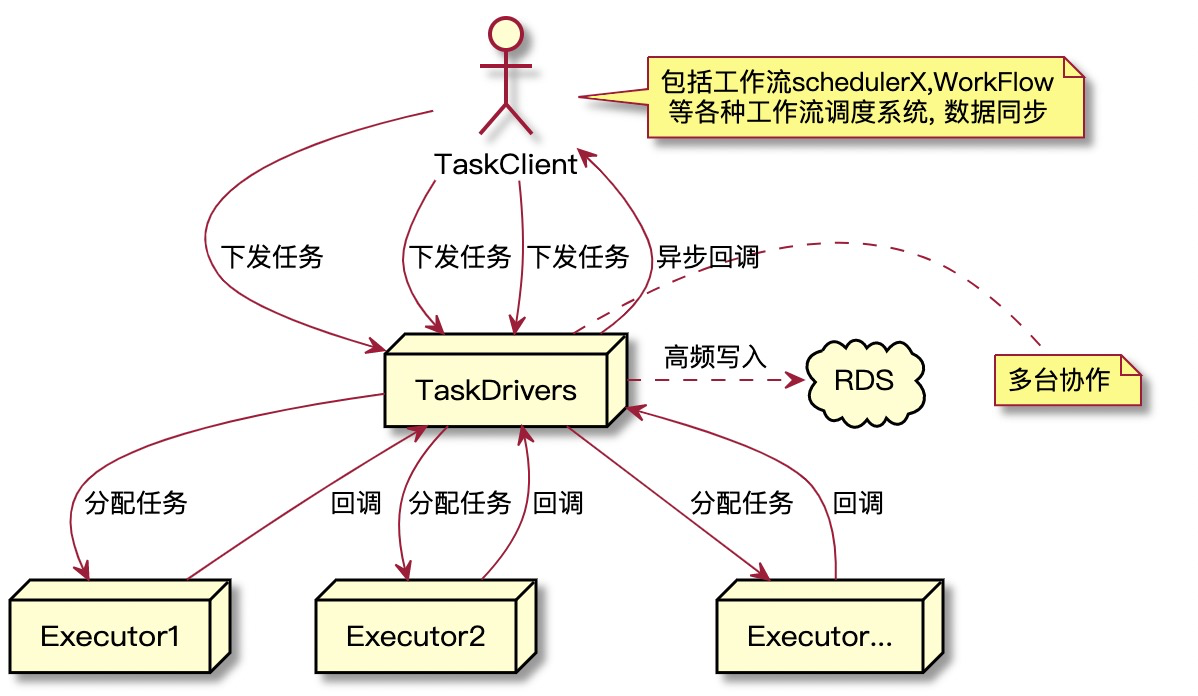
主要问题
任务执行引擎分为少量的driver(代理人)和成千上万的executor(执行者),这里剥除driver其他所有负责的功能,只说和整点洪峰相关的流程,任务接收和任务状态回调。整点到来时,来自各个接入客户端下发任务数量激增,这是第一道关,有点类似开闸放水,顷刻间任务全部被driver指派给executor去运行,executor的数量非常之多,客户端需要及时知道任务状态的变化,运行态的回调,即executor回调给driver任务状态,是下一次对driver的洪峰。而往往这两次洪峰短时间内是叠加的,进一步加剧driver的负载。
削峰填谷
最初我只想针对任务下发做优化,削峰填谷按照最简单的策略就是引入Buffer。
计划分三步走:
(1) 任务下发流程改造,下发经过简单校验数据直接扔进缓冲区(过渡期用RDS),新起工作线程异步去消费缓冲区任务。
(2) Driver其实已经分布式化,但部分内存数据仍然是每台driver全量保存,经过事件同步。改造流程干掉这些同步事件。
(3) 缓冲区换成消息队列or Redis,进一步加快任务生产和消费速度
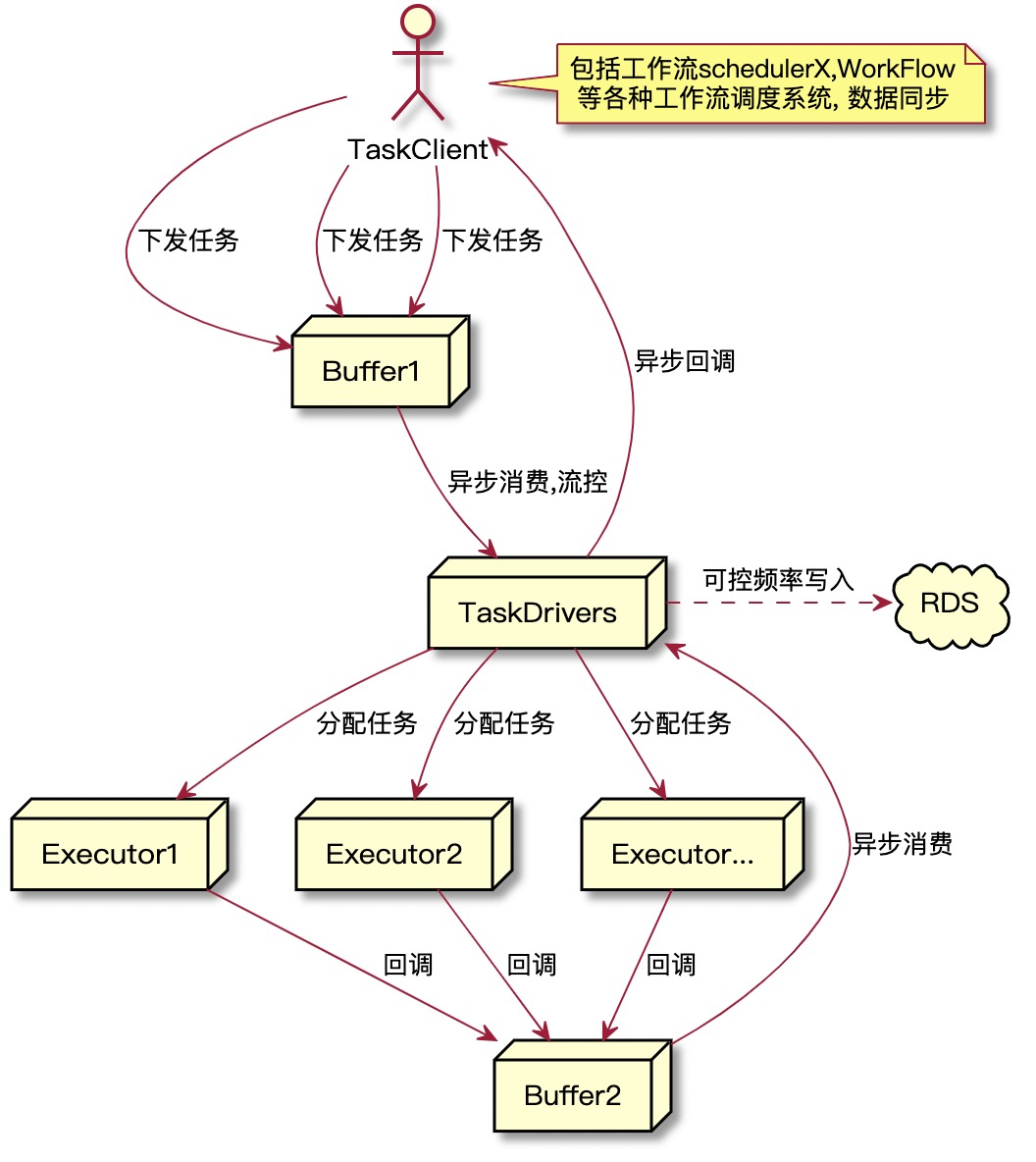
可是等第1、2步完成后发现,部署到开发环境后,QPS是上来了,但是RDS的TPS整点时还是很高,更细化的指标任务写入次数的确减少很多,但是发现整点的更新操作在靠近整点时间段反而更多,这么一均衡,整点的RDS负载其实没降多少。我忽略了一个点,也就是前面所提的任务回调这个流程所带来的请求洪峰,因为下发速度加快很多,导致回调洪峰整体提前,更加逼近整点。侧面看出我此次针对优化的分析缺乏大局观,因为这件事我悟到一些哲学上的事情,倘若自信满满在某个局部做到很好,事实也的确这样,但因缺乏整体链路的思考,往往其他问题会因你的局部努力会逐渐展现,或者已有的问题变得愈发严重。生活也类似,我的一个感觉,分享给大家不客气。基于此,开始着手将回调的任务数据也暂存到Buffer里批量消费。
进一步
倒不如再往远想一步,运行态的每一个具体的任务回调因为要经过driver层中转,这部分数据都需要持久化。干脆干掉这个中转持久化过程,executor回调状态给driver后不对数据持久化,driver直接回调给接入的客户端。聪明的小朋友问了:
1)其中一个客户端异常,回调总是失败,这样会不会导致executor回调队列的堆积?
不会,回调失败的任务数据会在driver层进行持久化,用于下一次driver主动重试,executor对应的数据会销毁。
2)如果不持久化数据任务状态怎么更新,以为客户端可能会主动查询执行系统的任务状态,是否会出现不一致?
不会,executor有心跳机制,定时的心跳包会批量带上任务状态的数据再次请求给driver,这会带来一定的延迟,可能有5s以内的延迟,但是离线任务的状态更新允许有一定延时,用户不会一直盯着。但是! !也有客户端对任务状态的即时更新非常敏感,比如用户的直接查询并且要当时就看到任务结果,或者作业运行速度很快。所以我们增加了一个配置,客户端分为敏感型和非敏感型,只有非敏感型客户端才会用这种新方式。对于我们平台来说,非敏感型的任务数量远超过敏感型。所以这个优化效益还是会被放大很多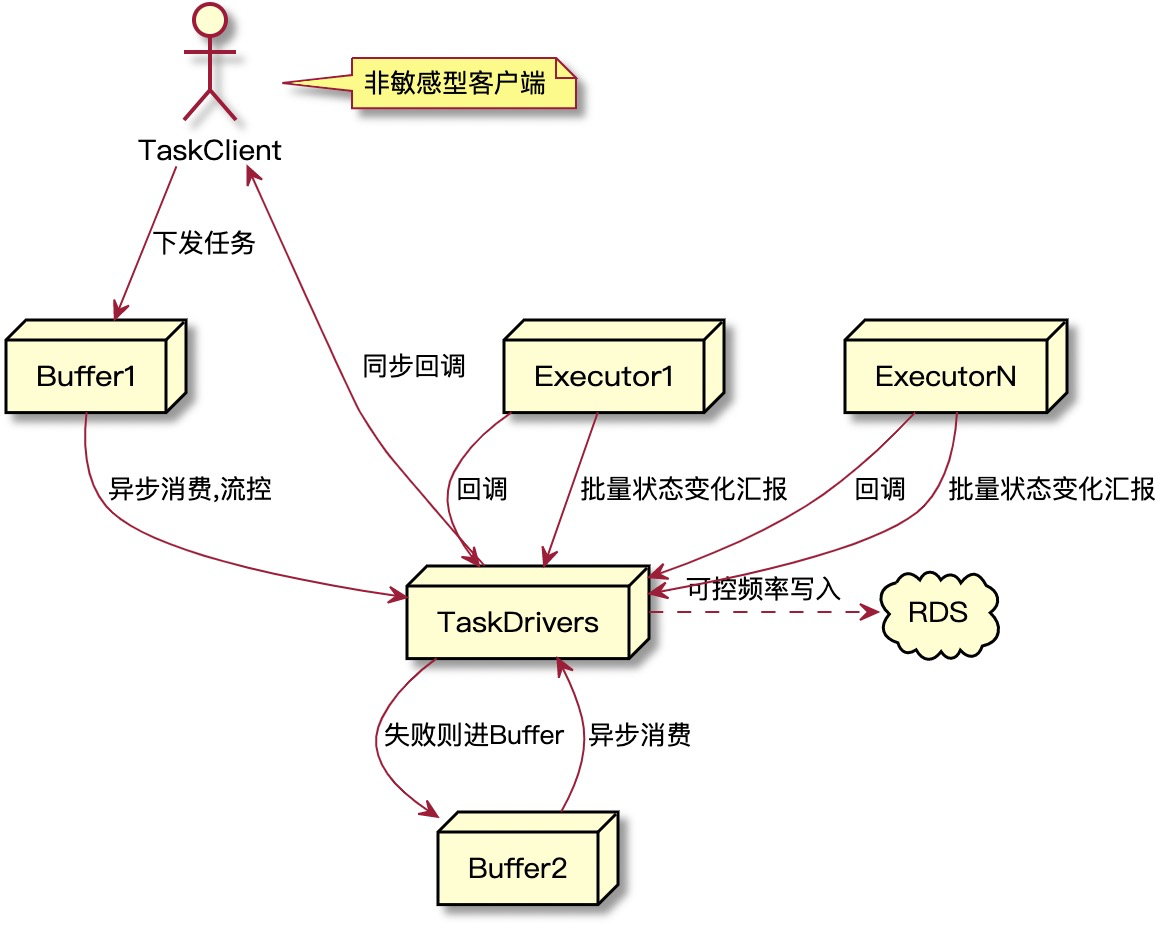
一些后续的话
最后,其实短期内的这一块的职业目标就是让它扩展性变得更强更灵活,以后任务量上去了,傻堆机器就行。这段时间也在和阳总讨论的两个里程碑:
执行任务executor动态扩缩容,大集群的自动切分,前提是我们有个类似大脑的角色去识别下发的任务是长任务还是短任务,包括其他特征(可能基于历史数据加规则)。
考虑引入k8s扩展我们系统的能力,其实我们系统本身就很像k8s,优势是比他们启动任务进程比k8s快,k8s是镜像级别的,多出镜像构建和部署这个步骤,而我们是软件级别的,软件需要提前在机器上安装好。但我们没有k8s那么灵活和开放,拥抱开源是大势所趋。
我心想着,这两件事(或者一件)做完落地,我也算完成了一个团队的重要使命。